A small side project that evolved from a simple daily crawler into a price prediction tool for New Zealand insurance auctions.
This is the final part of the NZ Car Auctions series: Part 1: building the dataset · Part 2: analytics with zero servers · Part 3: the prediction model (this post).
During time in New Zealand, buying and selling cars became a practical side hustle (the Garage on this site is basically the receipts). With a PhD-student budget, one workable approach was picking up damaged/rough cars, fixing them, and selling them on. Insurance auctions were a major source for those purchases.
The problem: “Is this a good buy?”
One of the auction sources used regularly was manheim.co.nz. After moving from New Zealand to Singapore, friends would occasionally ask for help spotting a good buy and estimating what a sensible price might be.
Over time, a rough intuition forms for what “good value” looks like for certain makes/models/years, but intuition has two problems:
- It requires checking listings constantly.
- It doesn’t scale when life gets busy (and the timezone changes).
That’s where tooling helps.
Step 1: a daily crawler
The first iteration was a web crawler that pulled down the day’s auction inventory and surfaced it as a simple list, hosted at findcars.prasanthsasikumar.com. (It has since grown into FindCars NZ, a full analytics dashboard with interactive charts, open data downloads, and a free JSON API; Part 2 covers how it works.)
That solved one part of the workflow: “What’s up for auction today?”
But it didn’t answer the harder question.
Step 2: logging everything (CSV over time)
A few months after the crawler went online, the missing piece became obvious: if listings and outcomes are logged over time, the result is a usable dataset. The scraped data started getting saved as a growing CSV. The full pipeline (GitHub Actions, cleaning, the gotchas) is Part 1 of this series, and the dataset itself is open on GitHub.
Once there’s a history of:
- vehicle attributes (make/model/year/odometer/etc.)
- auction context (date, listing details)
- observed prices
…it becomes possible to estimate what a “reasonable buy price” might be for a given listing, based on what similar cars sold for before.
Step 3: a simple model (XGBoost)
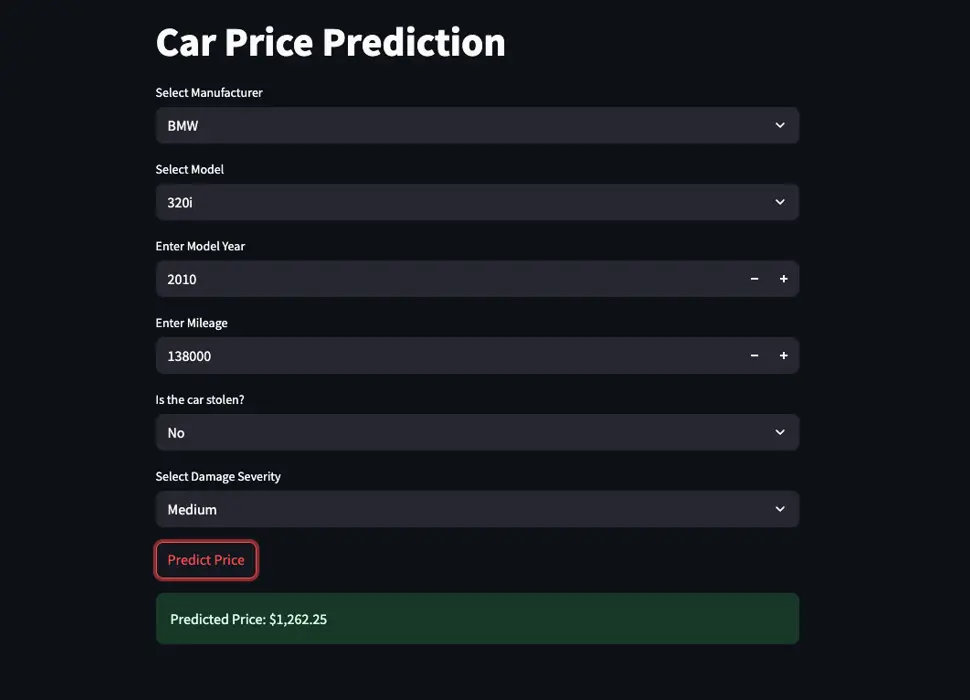
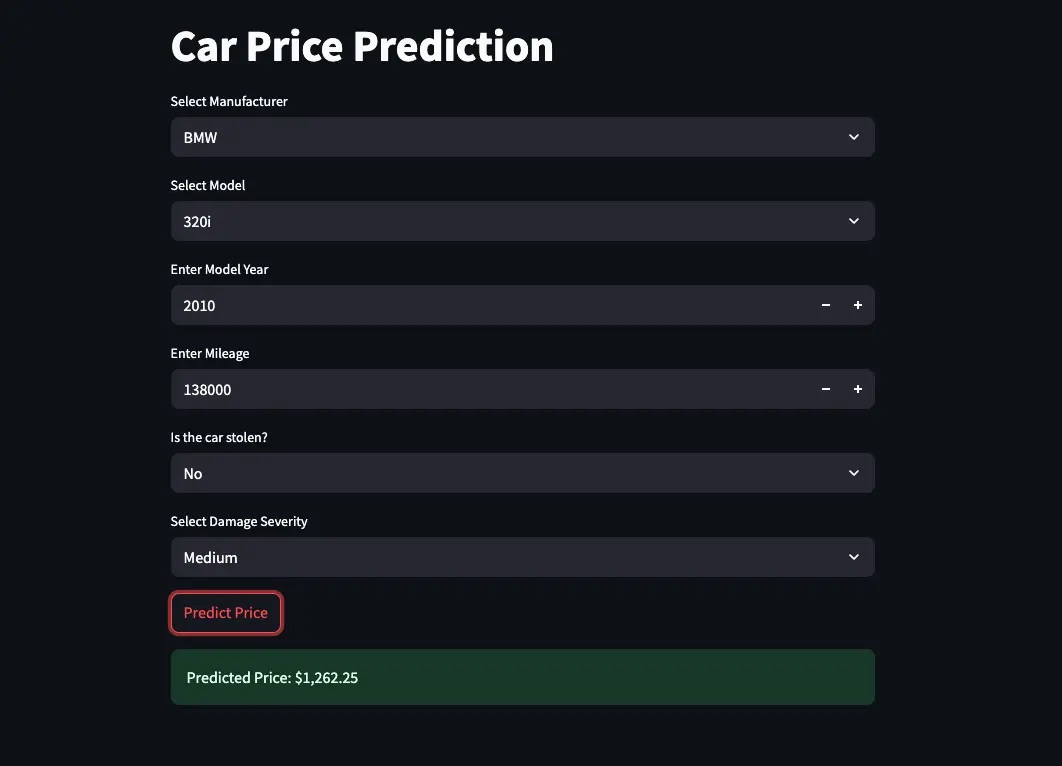
The prediction model is intentionally straightforward: an XGBoost regressor trained on the historical CSV. It’s not magic and it doesn’t pretend to be: it can only predict sensibly when it has seen enough similar examples.
The goal wasn’t academic novelty. It was a practical tool that can answer:
If this car is bought at around $X, is that a sensible number?
Step 4: putting it behind a UI (Streamlit)
To make it usable without copy/pasting data around, the predictor is wrapped in a Streamlit app and hosted here:
What worked (and what didn’t)
A few observations after living with it for a while:
- Logging consistently mattered more than model complexity.
- “Similar car” is doing a lot of work: trims, condition, and market shifts can dominate.
- The long tail is real: weird listings don’t have good comparables.
The whole toolchain, in one place: the FindCars NZ dashboard for browsing and analytics, the open dataset if you want to build your own model, and the price predictor to try this one. And if you want proof the loop actually closes, the garage is what came out the other end.